Datenbankmigration von MS SQL Server zu PostgreSQL
Eine praktische Anleitung am Realbeispiel
Von Wesner-Softwareentwicklung | Veröffentlicht am: 17.11.2025
Inhaltsverzeichnis
In der Welt der Softwareentwicklung und Datenbankadministration stellt der Transfer eines Projekts von einem Datenbanksystem (DBMS) zu einem anderen eine häufige Herausforderung dar. Ein typisches Szenario ist die Migration von einem kommerziellen Microsoft SQL Server zu seinem leistungsstarken und kostenfreien Open-Source-Äquivalent PostgreSQL. Auf den ersten Blick mag diese Aufgabe aufgrund der unterschiedlichen SQL-Dialekte komplex erscheinen, in der Praxis ist sie jedoch mit dem richtigen Vorgehen gut zu bewältigen.
Dieser Artikel dient als Ihre schrittweise Anleitung. Anhand eines realen Beispiels einer kleinen Firmendatenbank (Büro) wird demonstriert, wie Schema und Daten korrekt aus MSSQL exportiert und anschließend für PostgreSQL adaptiert und importiert werden.
Der Beitrag richtet sich an Junior-Entwickler, Datenbankadministratoren und alle, die vor einer ähnlichen Migrationsaufgabe stehen.
Verwendete Tools:
- SQL Server Management Studio (SSMS)
- pgAdmin
- Notepad ++
Schritt 1: Export von Schema und Daten aus dem MS SQL Server
Ein häufiger Fehler ist der Versuch, ein binäres Backup (eine .bak-Datei) zu erstellen. Dieses Format ist MSSQL-spezifisch und mit PostgreSQL inkompatibel. Die korrekte Methode ist der Export in Form eines SQL-Skripts, das die Befehle zur Wiederherstellung der Struktur und zur Einfügung der Daten enthält.
Vorgehensweise in SSMS:
- Im Objekt-Explorer wird mit der rechten Maustaste auf die Quelldatenbank (Büro) geklickt.
- Im Kontextmenü werden "Tasks" -> "Generate Scripts..." ausgewählt.
- Anschließend werden die zu exportierenden Objekte (alle Tabellen und Views) selektiert.
- Im Schritt "Set Scripting Options" wird ein Speicherort für die Datei gewählt und auf den Button "Advanced" geklickt.
- Im sich öffnenden Fenster muss die Option "Types of data to script" auf den Wert "Schema and data" geändert werden. Dieser Schritt ist entscheidend, da andernfalls nur die leere Tabellenstruktur exportiert wird.
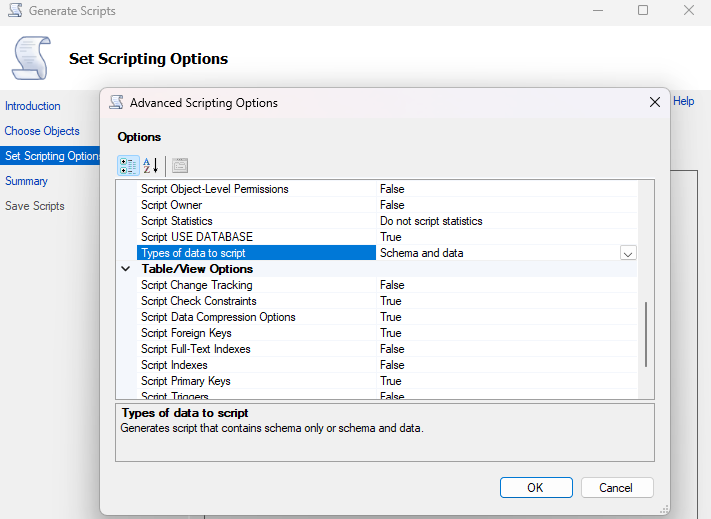
Ergebnis: Nach Abschluss dieses Prozesses liegt eine einzelne, große .sql-Datei vor. Diese Datei ist unser Ausgangspunkt. Sie enthält die gesamte Logik, ist jedoch im T-SQL-Dialekt verfasst, den PostgreSQL nicht direkt interpretieren kann.
Schritt 2: Analyse der Unterschiede: Die Dialekte T-SQL und PostgreSQL
Vor der direkten Ausführung des Skripts müssen die inkompatiblen Teile identifiziert werden. Obwohl beide Systeme SQL verwenden, unterscheidet sich die Syntax für einige Schlüsseloperationen erheblich.
| Aspekt | MS SQL Server (T-SQL) | PostgreSQL |
|---|---|---|
| Auto-Inkrement ID | INT IDENTITY(1,1) | SERIAL oder GENERATED AS IDENTITY |
| Text-Datentypen | NVARCHAR, NCHAR (für Unicode) | VARCHAR, TEXT (Unicode ist Standard) |
| Objektnamen | [dbo].[TableName] | tablename (wird in Kleinbuchstaben konvertiert) |
| Spezifische Befehle | USE, GO, SET IDENTITY_INSERT | Werden nicht verwendet |
| Schlüsselerstellung | PRIMARY KEY CLUSTERED (...) ON [PRIMARY] | PRIMARY KEY (deutlich einfachere Syntax) |
Für eine detaillierte Gegenüberstellung der beiden Datenbanksysteme empfehlen wir diesen umfassenden Artikel von Kinsta: https://kinsta.com/de/blog/postgresql-vs-sql-server/
Mit diesem Wissen kann die gezielte Anpassung des Skripts beginnen.
Schritt 3: Adaption des Skripts – Die Übersetzung von T-SQL nach PostgreSQL
Die generierte .sql-Datei wird in einem Texteditor geöffnet, um die "Übersetzung" vorzunehmen.
3.1 Bereinigung von MSSQL-spezifischen Befehlen
Zuerst werden alle Anweisungen entfernt, die ausschließlich für die Konfiguration des MS SQL Servers relevant sind. Dies betrifft zahlreiche Zeilen am Anfang und Ende der Datei:
- USE [DatabaseName]
- Alle SET ...-Befehle (z. B. SET ANSI_NULLS ON)
- Alle ALTER DATABASE ...-Befehle
- Der Batch-Trenner GO
3.2 Modifikation von CREATE TABLE
Dies ist der zentrale Teil der Anpassung. Am Beispiel der Tabelle Positionen:
Original im MSSQL-Skript:
CREATE TABLE [dbo].[Positionen](
[PositionID] [int] IDENTITY(1,1) NOT NULL,
[Positionsbezeichnung] [nvarchar](100) NOT NULL,
[Gehalt] [decimal](10, 2) NOT NULL,
PRIMARY KEY CLUSTERED
(
[PositionID] ASC
)WITH (PAD_INDEX = OFF, ...) ON [PRIMARY]
) ON [PRIMARY]
GOAdaptiert für PostgreSQL:
CREATE TABLE Positionen (
PositionID SERIAL PRIMARY KEY,
Positionsbezeichnung VARCHAR(100) NOT NULL,
Gehalt DECIMAL(10, 2) NOT NULL
);Der Code ist sichtlich sauberer und prägnanter. [dbo]. und die eckigen Klammern wurden entfernt, IDENTITY wurde durch SERIAL PRIMARY KEY und nvarchar durch VARCHAR ersetzt.
3.3 Vereinfachung von INSERT und VIEWS
Die INSERT-Befehle müssen von SET IDENTITY_INSERT und dem Präfix N vor Zeichenketten bereinigt werden. Der Code für CREATE VIEW erfordert glücklicherweise kaum Änderungen, da die JOIN-Syntax Teil des SQL-Standards ist.
Endergebnis: Das universelle "Master-Skript" für PostgreSQL
Nach allen Anpassungen liegt ein einziges, sauberes Skript vor, das zur Ausführung in pgAdmin bereit ist. Es erstellt die gesamte Datenbankstruktur von Grund auf, befüllt sie mit Daten und stellt die Views wieder her.
Wichtige Empfehlungen für die professionelle Praxis (Bonus-Abschnitt)
Die reine Adaption des Skripts ist nur die halbe Miete. Es sollte um einige Aspekte erweitert werden, um es robust und professionell zu gestalten.
Empfehlung 1: Synchronisation der Auto-Inkrement-Zähler
Problem: Durch das manuelle Einfügen von Daten mit spezifischen IDs (INSERT ... (PositionID, ...) VALUES (1, ...)), ist der interne Zähler des SERIAL-Typs in PostgreSQL nicht mehr synchron. Der Versuch, einen neuen Datensatz hinzuzufügen, würde zu einem "duplicate key"-Fehler führen.
Lösung: Nach allen INSERT-Befehlen müssen spezielle Funktionen ausgeführt werden, die PostgreSQL den aktuellen Höchstwert für jeden Zähler mitteilen.
-- Synchronisation der Zähler für SERIAL-Felder
SELECT setval('positionen_positionid_seq', (SELECT MAX(positionid) FROM positionen));
-- ... usw. für alle Tabellen mit SERIAL-SpaltenDies ist ein obligatorischer Schritt für den korrekten Betrieb der Datenbank nach einem manuellen Datenimport.
Empfehlung 2: Beachtung der Groß- und Kleinschreibung!
Problem: MSSQL hat die "CamelCase"-Schreibweise (PositionID) beibehalten, während PostgreSQL standardmäßig alle Namen in Kleinbuchstaben (positionid) konvertiert hat.
Empfehlung: Es ist ratsam, diesen Standard von PostgreSQL zu akzeptieren (Kleinbuchstaben und bei Bedarf snake_case, z. B. position_id). Dies vereinfacht zukünftige Abfragen erheblich und vermeidet Verwirrung.
Fazit
Wie sich zeigt, ist eine Migration von MS SQL Server zu PostgreSQL mehr als nur "Kopieren und Einfügen" – es ist ein durchdachter Prozess der syntaktischen Anpassung. Durch das Verständnis der wichtigsten Unterschiede in den SQL-Dialekten und die Anwendung der Best Practices des Zielsystems kann der Übergang reibungslos und zuverlässig gestaltet werden.